Staying on-top of the latest adversarial methodologies means quickly adjusting to new TTPs and requires a thorough and constant understanding of your own detection capabilities. Given a rapidly changing, dynamic environment, this level of attention can't be a manual process, it requires the magic of automation.
MITRE's ATT&CK Framework provides an awesome way to more systematically analyze what you need to be detecting (techniques) and some of the places you should be gathering from (data sources). They even provide a mapping of data source to techniques to help determine where you could detect a technique.
Great! Problem solved then right?
Not quite.
While this is a solid start to determine what an organization COULD be detecting, it doesn't address what you actually are capable of detecting. There are two parts to "actual": what data is available and how are you analyzing said data.
Measuring Available Data
Measuring the availability and quality of data sources is critical in determining the techniques which could possibly be detected. Without relevant data sources, an analyst is unable to create rules or signatures to detect techniques (no data source == no data), and therefore coverage gaps exist.
Understanding what data sources are available also allows analysts to analyze existing rules and determine gaps in possible coverage. E.g. a data source has the data to provide visibility on a technique, but no rules exist to detect said technique.
Tools such as Rabobank's DeTT&CT, ATTACKdatamap by Olaf Hartong, and ossem-power-up exist to create "heatmaps" of data source coverage but rely on manual analysis of data sources to determine availability and quality.
Here, we want to maintain a real-time, accurate map of actual data sources generating actual data.
Lucky for us, Graylog, Splunk, or [insert the log aggregation tool or SIEM you use] likely provides an API which you can query. Configurations stored in object storage or code repositories can be pulled and analyzed.
We accomplish this by querying our infrastructure (Graylog, git, AWS) in real-time to gather available data sources and calculate the quality of said data sources. The final product returns what is actually running, right now.
Mapping Actual Sources to MITRE ATT&CK
What constitutes an actual "data source" and how that actual data source maps back to MITRE's terms is somewhat subjective. The intent here is to do the subjective work upfront, and create a mapping between terms, configurations, or collections which can be automatically updated as infrastructure is updated.
For example, ATT&CK has a data source "Application logs". This could mean logs created by a custom application and stored at /var/log/someapplication/*.log or it could mean the Application Log Event Log within a Windows 10 client.
On the other side of the map is the real-world data collected. Data collected is a function of: the tool used to collect [Sysmon, Winlogbeat, Filebeat, etc.], the configuration of the tool, and the role of the endpoint.
For example:
- Winlogbeat and Sysmon running on a Windows Domain Controller could map to different data sources than the same tools running on Windows 10 user endpoint.
- Winlogbeat running alone and collecting event logs on a Windows 10 endpoint will map to different data sources than with included Sysmon on the same endpoint.
- Winlogbeat configured to exclude VPN logs on an endpoint maps to a different set of data sources than the same tool running without exclusions.
So, we need to analyze where the information is coming from, how it's being gathered, and how the collection tools are configured. With this analysis in place, we have a pretty good idea of what techniques we could possibly detect, and which ones we would likely never notice, lacking the necessary data.
If we are collecting logs from /var/log/nginx/nginx.log, we have some coverage on the Web Proxy data source. If we have zero inputs from Amazon Web Services, it's unlikely we have coverage for AWS CloudTrail Logs.
Once we determine MITRE ATT&CK sources available, it's a simple mapping between technique <-> data source to determine which techniques we can cover. We build the final product out as a .json layer for ATT&CK Navigator as exampled below.
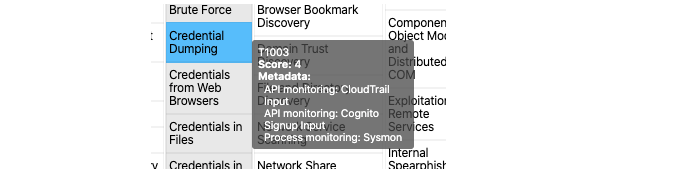
- Note that the
scorefield indicates the relative quality of coverage for that specific technique, as related the available data sources. Themetadatafield describes where the coverage is coming from and the associated data source.
Mapping Technique Detection to MITRE
With an objective picture of what we COULD detect, we now need to analyze what we are CONFIGURED to detect.
Pipelines and rulesets provide the "ground-truth" on what can be detected. Within a data source, if no rule exists to detect a specific technique, it is highly unlikely an analyst will ever see any evidence of the technique within the noise (no signatures == no detection).
By analyzing your existing rulesets programmatically, you can once again automate (HOORAY AUTOMATION!) the creation of real-time mappings of detection capabilities. We can read our system rules, determine which techniques we can identify, and then map that back to MITRE ATT&CK.
Behold, a real time visualization of technique detection capabilities!

Why Automate it?
Defining relationships up front allows us to query our infrastructure at any point, gather the configurations, and generate a current, objective picture of what our possible detection capabilities are.
This could be done subjectively, by looking through data sources, building a map, and storing it for posterity, but, the moment your Sysmon configuration changes, or a Filebeat path is updated, that picture is now dated, and you have lost visibility on your actual capabilities.
An even better approach is to trigger a rebuild on updates to the infrastructure.
Because defining things "as code" is awesome, our rules, many of our system builds, and our software configurations are easy to analyze (and can trigger actions whenever they are modified!)
Update the Sysmon configuration: BAM, new heatmap.
Update the Filebeat paths for a log input: BAM, new heatmap.
AND ATT&CK Navigator can be easily self-hosted (and should be if you are importing sensitive data like this) which allows us to quickly and easily import layers automagically from CI jobs.
What Now?
With the ability to see what we could detect vs what we have rules built for, our gaps become evident and we can start improving both the sources we collect and the rules in place for detection.
As the entire process is automated, we can quickly respond to a new adversarial TTP and focus on improving our coverage, rather than spinning cycles on recovering what our current capabilities are.
If you are interested in learning the specifics of how we do this, reach out, check us out at Black Hat USA 2020 here and here, or join us for OpenSOC in the Blue Team Village at DEF CON 28 this year!
Also, check out MITRE's ATT&CK Navigator for excellent documentation on how to self-host and customize it for cases just like this.