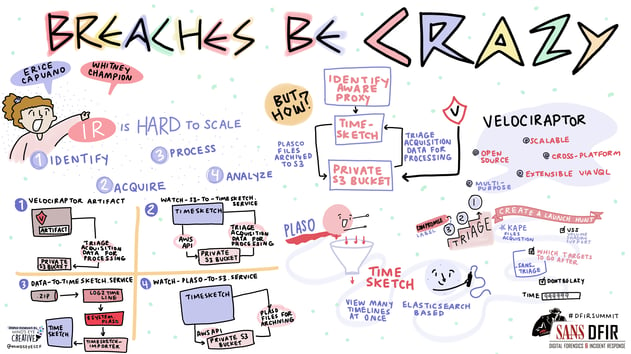
In July, Eric & Whitney gave a talk titled "Breaches Be Crazy" at the SANS DFIR Summit outlining Recon’s unique approach at scaling enterprise forensic timelining.
The issue that pushed us to innovate in this area is one that most incident response teams face: acquiring, processing, and analyzing forensic data from large scale intrusions can be incredibly time consuming and difficult to scale.
While the analyzing of forensic data still requires highly skilled and experienced examiners to spend many hours finding needles in many hay stacks, we sought to significantly speed up the acquisition & processing steps.
A typical Incident Response scenario requires an examiner to take the following high-level steps:
- Scope - Identify which systems are likely compromised, usually based on initial indicators (IDS/EDR/SIEM alert, etc)
- Acquire - Perform forensic acquisition of scoped systems
- Traditional Approach - Can take one to many hours per system
- Our Approach - As fast as 8 minutes per system
- Process - Processing of raw forensic data acquired from scoped systems
- Traditional Approach - Often takes many (6+) hours per system, processed one at a time
- Our Approach - Generally an hour or less per system, can be processed in parallel
- Analyze - Begin analysis of processed forensic data
- Many (4+) hours per system
Now imagine how time consuming an investigation could be for an intrusion involving 20+ systems! Without taking a long hard look at your processes, you could be wasting a lot of time and resources trying to scale traditional IR approaches. Our approach still follows this same set of steps but we’ve eliminated as much of the manual, unscalable, and time consuming pieces as possible.
Imagine a scenario where an organization is breached and the number of compromised systems are in the double (or even triple) digits. Like many organizations, this one does not have a SIEM or log aggregation point.
- Scope
- Traditional Approach - Without a well-tuned SIEM in place, it may be next to impossible to even know which systems are in scope and need to be examined. A traditional approach would struggle to know which systems to prioritize. Often times educated guesses are made as to which systems forensic data should be acquired from.
- Our Approach - There is much less need to determine entire scope right away, as we can quickly hunt for in-scope systems as soon as we deploy Velociraptor. We are able to begin acquisitions of known compromised systems, while simultaneously hunting for new ones. If the situation warrants, our approach enables us to simply consider “all” systems in scope, as we are able to process immense amounts of data providing a type of retro-active SIEM.
- Acquire
- Traditional Approach - Depending on the acquisition method (full disk or triage), this step can waste a lot of time. The traditional IR approach often resembles an inefficient loop between steps 2 & 4 in the process above, wasting many hours performing acquisitions on new systems as they are found to be in scope.
- Our Approach - Leverages triage acquisitions via Velociraptor, which significantly cuts down on the time and storage required to collect data from numerous systems.
- Process
- Traditional Approach - Once the examiner gathers the raw forensic data, the next hurdle is finding a way to process it at scale. This is less an issue when the intrusion involves 1 or 2 systems, but beyond that, it presents several challenges. Most processing tools available today are very time consuming and designed to process a single system at a time. Furthermore, few (if any) support any form of automation to enable an examiner to quickly process many systems back-to-back. Most of these tools are designed to be run on a single workstation by a single examiner which creates additional bottlenecks, especially in large intrusions or with IR teams of more than one person.
- Our Approach - Velociraptor acquisitions are automatically sent to Plaso for processing. We run Plaso on secure, high-compute cloud instances in order to process huge amounts of forensic data faster than any other known approach. Once processed, the timeline data is automatically sent to Timesketch for analysis.
- Analyze
- This is, and will likely always be, the most time consuming step. No matter how fast you become at the previous steps, this one cannot be automated or innovated away. Analysis of forensic data requires skilled, experienced examiners. If you are looking for DFIR training in this area, Eric also teaches SANS FOR508 which covers this exact type of analysis. See his course schedule here. The process improvements we can share about the analysis step is in our use of Timesketch, which is ideal for large-scale intrusion analysis and/or IR teams with multiple analysts. Recently, Timesketch gained Sigma integration which is a promising feature to help automate some threat detection within timelines.
Technical Benchmark Details
To get an idea of how fast this process can be from start to finish, we ran a benchmark with the following systems:
- Triage Victim: Windows 2016 Domain Controller
- Velociraptor Server: t3.large, 2 vCPU, 8G mem
- Timesketch Server: c4.4xlarge, 16 vCPU, 30G mem
- (~8 minutes) Triage acquisition included everything in the
!SANS_Triage.tkapeKAPE Files target. Generated a 4.2GB triage zip. - (~15 minutes) Plaso is ran against the triage files using this command. Generated 5.6M events.
- (~45 minutes)
timesketch_importer.pyindexes the Plaso timeline events into Elasticsearch, and then adds the timeline to Timesketch, using this command.
Want to try it out?
Check out our GitHub repo containing the custom artifacts and service files needed to build these automations and integrations.
Need Help?
Are you experiencing a possible breach and need expert guidance? Contact us for immediate assistance.