Now that we've normalized and enriched our events, let's get into the actual threat detection logic that brings SIEM-like features to open source Graylog.
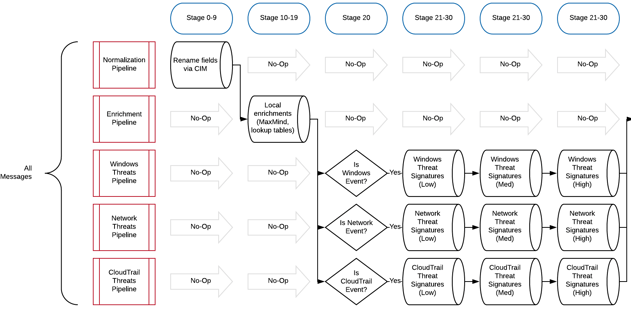
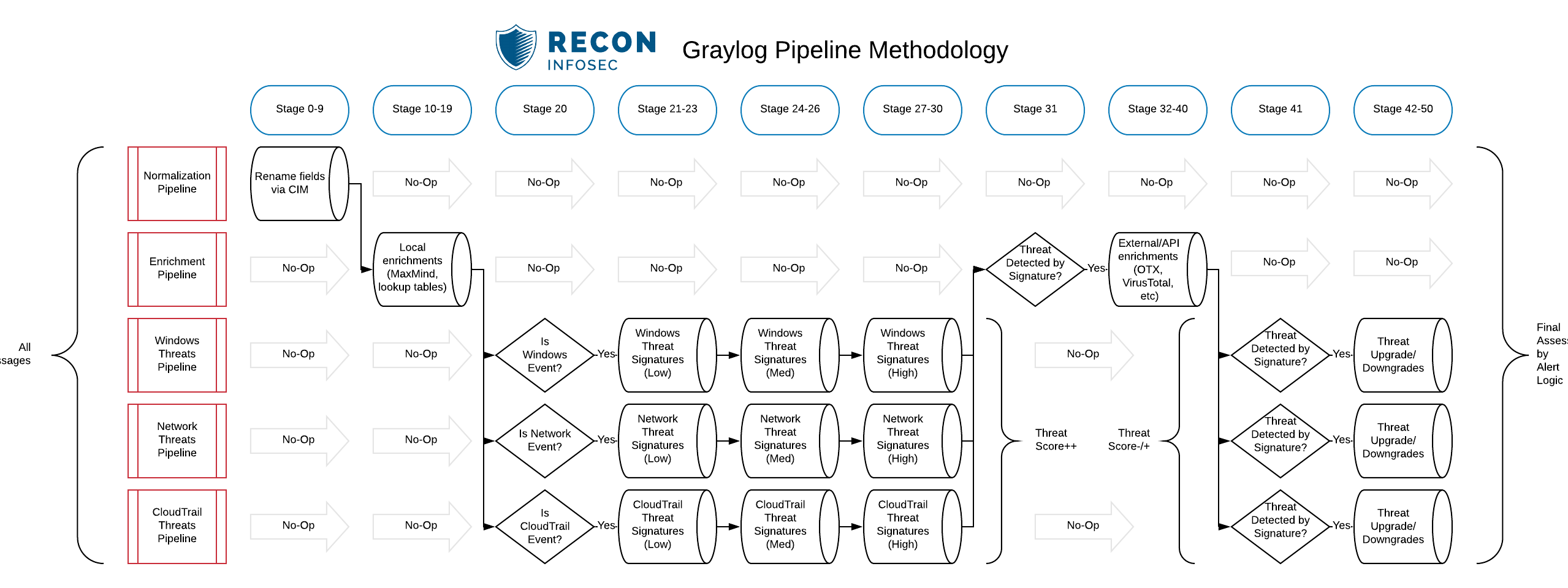
As you can see in the diagram above, we perform normalization, enrichment, and threat detection in standalone pipelines. This allows far more granularity and control over how the messages flow through many stages of rules.
For instance, it would not make sense to send Linux syslog events through a pipeline containing Windows threat signatures.
However, since Linux syslog may also contain network information (UFW, iptables, etc), we can choose to send those messages through more than one applicable pipeline.
We handle this routing logic in Stage 20 of our hypothetical example.
DETECTING THREATS IN WINDOWS PROCESS CREATION EVENTS
Let's say we wanted to develop a pipeline for analyzing Windows Process Creation events for threats or anomalies.
The first stage of this pipeline should come after the normalization and enrichment stages--let's call it stage 20. Stage 20 would contain only a single rule which serves to pass only relevant events to the rest of the stages of this pipeline. Here's an example of such a rule.
rule "pass_win_process_creation_only"
// to ensure that all subsequent stages only process relevant events
when
( // native event ID 4688
has_field("event_type") AND
to_string($message.event_type) == "wineventlog" AND
has_field("event_id") AND
to_string($message.event_id) == "4688"
)
OR
( // sysmon event ID 1
has_field("event_type") AND
to_string($message.event_type) == "sysmon" AND
has_field("event_id") AND
to_string($message.event_id) == "1"
)
then
// pass this message to subsequent stages
endNotice this rule actually does not take any actions inside of the then block. This is our workaround for using a Pipeline rule that simply exists as a flow controller for stages that come after it. Any messages not matching this rule will not be passed to subsequent stages.
Now that we know that stages 21 and beyond will only ever see Windows Process Creation events, we can begin crafting threat signatures that are applicable to these events without worrying about wasting CPU cycles.
Great, so where can I find some solid inspiration for threat rules to build into my pipeline?
I'm so glad you asked! You can find nearly everything you need in the Sigma project created by Florian Roth. Even more specific to this example, look at the many existing rules for Windows Process Creation.
Let's use this rule as our example, win_susp_schtask_creation, which is looking for creation of scheduled tasks that do not match known common tasks. Now to be clear, this would be considered a very low risk, high false-positive signature, but we'll address that later in this post.
We must examine the logic of this Sigma rule and convert it into a Graylog pipeline like this (I added some additional exclusions as an example):
rule "persistence_susp_schtask_creation"
// https://github.com/Neo23x0/sigma/blob/master/rules/windows/process_creation/win_susp_schtask_creation.yml
// https://attack.mitre.org/techniques/T1053/
when
(
has_field("process_name") AND
has_field("command_line") AND
ends_with(to_string($message.process_name), "schtasks.exe", true) AND
contains(to_string($message.command_line), "/create", true)
)
AND NOT
// Events to filter out
(
( // ignore SYSTEM created tasks
has_field("domain_username")
AND
to_string($message.domain_username) == "NT AUTHORITY\\SYSTEM"
)
OR
( // Dell Command Update
has_field("process_parent")
AND
ends_with(to_string($message.process_parent), "DellCommandUpdate.exe", true)
)
OR
( // Microsoft Office ClickToRun
has_field("process_parent")
AND
ends_with(to_string($message.process_parent), "\\Program Files\\Common Files\\microsoft shared\\ClickToRun\\OfficeClickToRun.exe", true)
)
// etc, etc
)
then
set_field("threat_detected", true);
set_field("threat_name", "persistence_susp_schtask_creation");
set_field("threat_desc", "Detects the creation of scheduled tasks in user session");
set_field("threat_tactic", "persistence");
set_field("threat_technique", "scheduled_task");
set_field("threat_score", 2);
set_field("threat_id", "T1053");
set_field("threat_count", to_long($message.threat_count) + 1);
end
Notice all of the fields we are setting if the conditions are true:
threat_detected:trueallows analysts to easily query for all threats over a period of time and allows for subsequent pipeline rules to treat this message differently because of a potential threat being present (ie. expensive enrichment)threat_nametells the analyst the name of the threat rule that identified this event as a threat, allowing for quick rule analysis and tuning if needed.threat_descadds a friendly description of the threat to the event itself.threat_tactic/threat_technique/threat_idall provide MITRE ATT&CK context to the signature.threat_scoreis arguably most important here because this is how we later decide the alert action that should take place for this event.threat_countprovides a running count of how many threat signatures fired against this event. This is helpful because an event firing on a single low-risk threat is no big deal, an event that matches many low risk threats might be suddenly more important.
ASSIGNING AND ELEVATING THREAT SCORES
We adopted a threat scoring system that accounts for severity of a threat as well as prevalence of false positives.
For instance, a threat score 1 is assigned to a low threat that is known to have a high false positive rate. A threat score 9 is a high threat with virtually zero false positives.
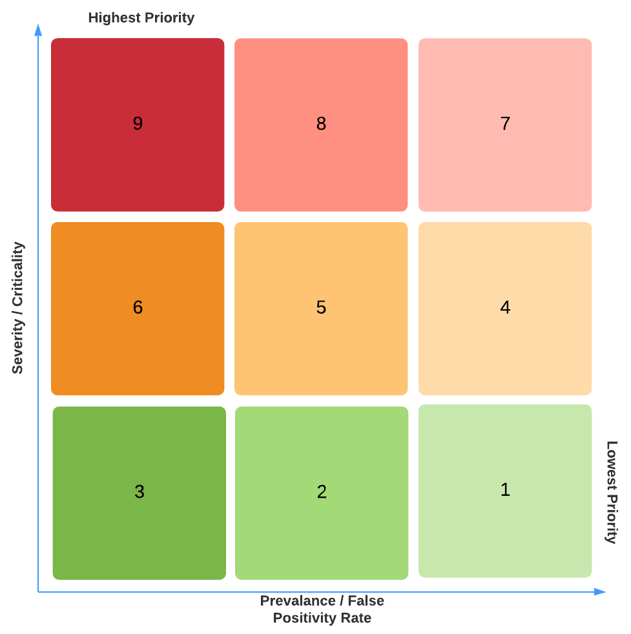
Now let's discuss how we distribute our threat rules to guarantee that we prioritize high-risk threats over lower risk threats. The challenge here is that the threat_score field will be overwritten if another rule matches the event in a later stage, so we want to ensure that the higher threat_score is written later in the pipeline.
Our pipeline and stage layout for this would resemble the diagram below.
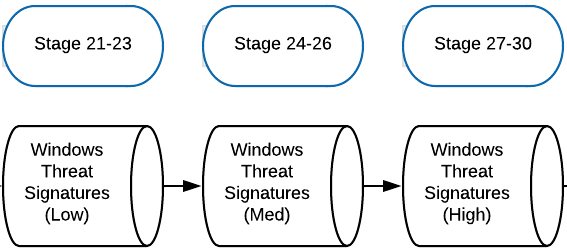
This means that even if a "low" threat is detected in an early stage, the final threat_score will be assigned by the highest threat which matched the event.
- Stage 21 -
threat_score:1(low severity, high false-positive) - Stage 22 -
threat_score:2(low severity, medium false-positive) - and so on...
Now you'll understand why the example rule above had a threat_score:2, because scheduled tasks are created all the time and would generate a lot of alerts if not kept in check.
Let's say we had threat intel on APT group "Winnie the Pooh" which revealed a piece of malware that creates a Scheduled Task named tigger on the infected endpoint by shelling out to schtasks.exe. This would present a very high confidence threat signature as /TN "tigger" is not something we'd expect to see in a healthy environment. We'd put this higher threat rule in a later stage, such as stage 29.
So let's produce a quick Process Creation threat signature for this:
rule "persistence_APT_winnie_the_pooh"
//
when
(
has_field("process_name") AND
has_field("command_line") AND
ends_with(to_string($message.process_name), "schtasks.exe", true) AND
contains(to_string($message.command_line), "/create", true) AND
contains(to_string($message.command_line), "tigger", true)
)
then
set_field("threat_detected", true);
set_field("threat_name", "persistence_APT_winnie_the_pooh");
set_field("threat_desc", "Scheduled Task Name associated with APT");
set_field("threat_tactic", "persistence");
set_field("threat_technique", "scheduled_task");
set_field("threat_score", 9);
set_field("threat_id", "T1053");
set_field("threat_count", to_long($message.threat_count) + 1);
end
Even though this message would've first matched our earlier rule titled persistence_susp_schtask_creation and been given a threat_score:2, this later rule would overwrite all threat_* fields with this higher severity threat. However, we would still know that a previous rule matched due to threat_count being 2 in this instance. Most importantly, we now know we have a threat_score:9 on our hands which would trigger immediate alerts/SMS/phone calls/etc to our SOC crew.
As I am sure you can imagine, these rules can become very complex and numerous.
UPGRADING THREAT SCORES WITH CONTEXT
What if we wanted to elevate a threat score according to asset value or some other data point?
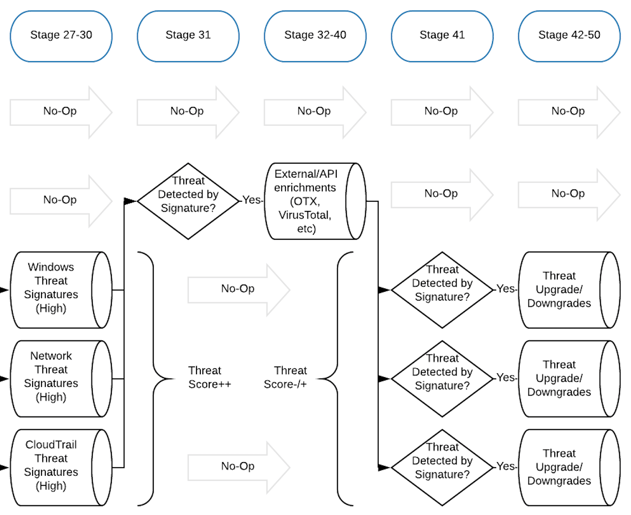
Let's say all Domain Controllers in our environment have predictable hostnames such as dc-1 and so on... This would allow us to more easily isolate these systems in a pipeline rule to elevate the threat score of an event that is impacting them. Scheduled tasks are a good example here because while they are prominent across most environments, they shouldn't change incredibly often on key terrain such as a Domain Controller.
We could simply add a rule in a later pipeline stage to upgrade the threat score on messages where hostname:dc*.
rule "upgrade_threats_on_domain_controllers"
when
to_bool($message.threat_detected) AND
has_field("hostname") AND
begins_with(to_string($message.hostname), "dc", true)
then
// raise the threat score by 3
set_field("threat_score", to_long($message.threat_score) + 3);
end
DOWNGRADING THREAT SCORES WITH CONTEXT
What about the many situations where a threat exists, but can be downgraded based on additional context? A good example is when you detect suspicious web requests being made against a web server, but the server is responding with non-2xx responses. While it's still noteworthy that the server is being scanned, the threat is minimal until the requests start succeeding.
For context, we have a threat rule for detecting many different known malicious strings in user-agent, uri, etc. for detecting vulnerability scanners and offensive tools. This threat rule is in the 21-30 stages. In stages 31, we have various "threat handling" rules which account for known risk-reducing situations such as the following:
rule "http_non_200_response"
// this rule is meant to downgrade a threat if related to an unsuccessful HTTP request
// such as a request to a non-existent resource which could be a precursor to attack,
// but not a threat by itself.
when
(
has_field("threat_detected")
AND
has_field("http_response")
AND
to_long($message.http_response) > 299
)
AND NOT
( // Do not downgrade nmap
has_field("request")
AND
contains(to_string($message.request), "nmap", true)
)
then
set_field("threat_score", 1);
set_field("threat_downgraded", true);
set_field("threat_handling_rule", "http_non_200_response");
set_field("threat_handling_desc", "This HTTP request was likely not successful due to a non-200 response code. A threat may still be present.");
end
Notice how we've added a couple new fields to the event.
threat_downgradedto inform the analyst this threat was originally higher, but was intentionally reducedthreat_handling_ruleto inform the analyst which rule performed the downgrade actionthreat_handling_descprovides a brief description of why the event was downgraded
As you can imagine, there are many different ways you can upgrade or downgrade a threat based on additional information. This step becomes critical before you start generating alerts that will flood the SOC and cause late night PagerDuty calls.
{kind=link}
WHAT NEXT?
Now that you've leveraged pipeline rules to look for known threats:
- Leverage the
threat_detectedfield to then route these messages for additional, more expensive enrichment like external API-based datasources. - Manage Your Rules on GitHub and Deploy them Automatically with CI
- Automatically generate ATT&CK Coverage Maps of your threat rules
- Want to know more about our approach? Ping us on Twitter and we'll elaborate where we can: @eric_capuano and @LukeRecon for pipeline architecture and rule development, and @shortxstack for all backend deployment stuff.
LOOKING FOR EXPERTISE?
The Recon team consists of passionate experts that eat, sleep and breathe defensive security operations. If you are looking for a partner, check out our services or contact us.