When I joined the OpenSOC team at the beginning of this year, everything resided on 3 Intel Skull Canyon NUC's, a couple other systems for scenarios or applications with hardware requirements, a Ubiquiti WAP, a Synology NAS, and various other things.

It has since gained a NUC, we replaced a system due to a failed hard drive, we no longer have to use the WAP since we have adopted ZeroTier and are also able to run on cellular if necessary, and OpenSOC overall has undergone some serious restructuring, re:infrastructure.
The NUCs are ESXi servers, running a complete enterprise environment. Windows systems (20+), directory server, mail generation, traffic generation, firewalls, you name it. Plus various other windows and linux systems to support some of our scenarios, all the systems for the red team activity (can't have a CTF without a Kali VM or 2). There's a lot going on.
When we (and mostly Eric, this is his brainchild) initially built it, all of the DFIR systems (Graylog, Kolide, Wazuh, moloch, GRR) were running on the same vSphere ESXi cluster as the windows environment. That's like 10 more resource intensive VMs.
It's a lot.
So in addition to hitting resource limitations, we were having to make sure we balanced said resources across each hypervisor, especially at boot before every event. We also started having issues with the dswitch configurations and connectivity dropping randomly, Eric had to completely reinstall vSphere at one point, and I don't even remember all of the other things. A lot has happened in 6 months.
Keep in mind, this is not our day job. This is what we work on until our eyes bleed at 4 in the morning. It is absolutely a passion/borderline obsession.
We decided to make a big change, to hopefully alleviate a lot of our issues, and make our event more scalable: move the DFIR systems to AWS, but still be able to fall back to the range systems.
Let me stop right there for a moment to shed some light on the situation at hand. I was asked to rebuild this entire environment, to scale, and automate all of it. this is the equivalent of kid in a candy store for me.
So I got to work. I had already automated a LOT of the pieces that I needed in order to do this. My tools of choice? AWS CloudFormation, and Ansible.
I know some of you will scoff at one or both of those and be like, why didn't you use terraform? Or GCP? Anything else? TL;DR: Ansible is my bread and butter as much as AWS is. I had a lot of the heavy lifting already written. And I know it works.
Curve ball: all of our *nix systems are ubuntu. Coming from a former fedora fan girl and official Red Hatter, my instinct these days is to type apt instead of yum or dnf. I am so conflicted (but no one will ever take my vim away).
Visual representation of our current stack:
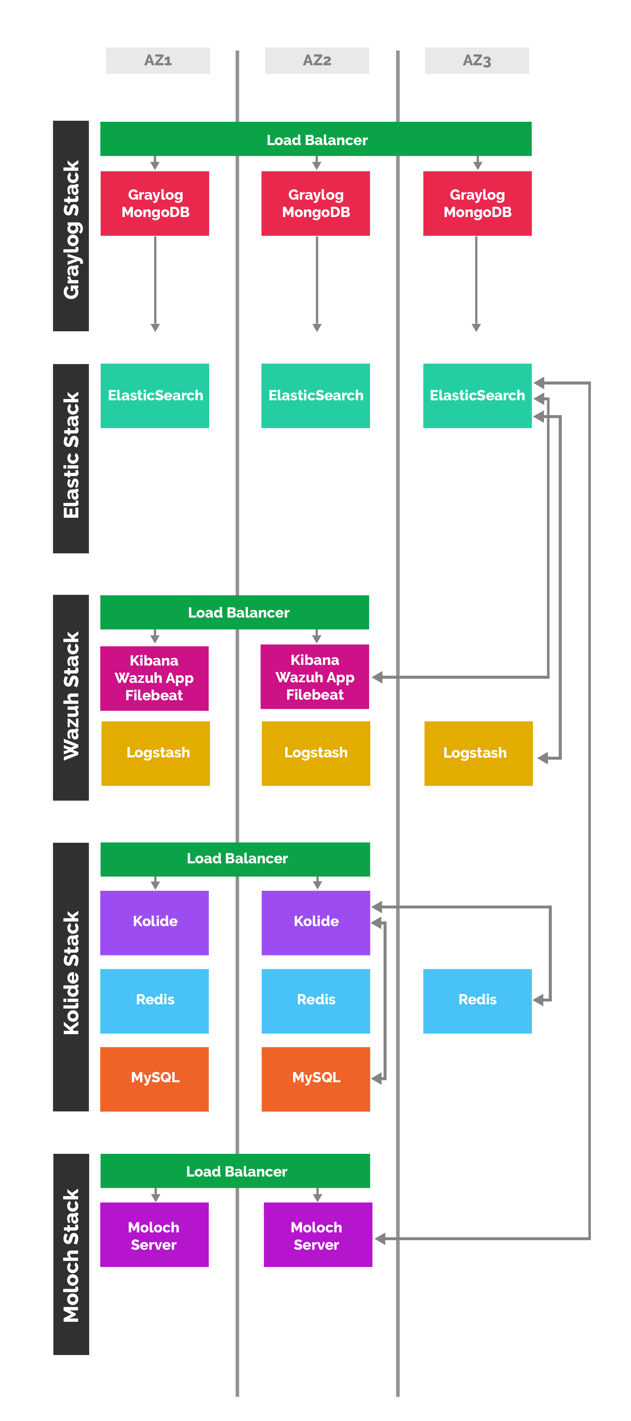
When we deploy our current stack, it builds the following, configured and ready to be hit by all of our windows systems and sensors in the range:
- our VPC
- subnets (omg so many subnets, like 40, network segmentation and HA FTW)
- routing tables
- NACL's
- bastion
- VPN server
- VPN tunnel to the range
- security groups (again, so many)
- load balancers (classic or application, depending on what each setup needs, and sometimes multiple load balancers depending on public or private access)
- target groups
- DNS/route53 entries
- Elasticsearch cluster
- Redis cluster
- MySQL
- Mongo replica set
- auto scaling groups (for graylog, wazuh, kolide, moloch, GRR, nginx, etc)
- launch configurations / user data
- Mailgun configurations for services that need it
- ECS services, for things that need to be dockerized (see tangent below)
There are also pieces in there that run after everything is built. once the above CloudFormation stack is done and Ansible deploys all of those applications and configures everything, the playbook continues on to install New Relic agents, Telegraf agents, Graylog sidecar collector / osquery / Wazuh OSSEC agents on all of our own systems (FUN FACT: we monitor OpenSOC with our production stack!), and then add everything that needs to be user-facing to ZeroTier.
If you're curious, the Ansible roles directory that this runs from? 47 roles. It is no joke.
You guys. In a single build.
To clarify, this is very much our environment when it builds. This isn't a vanilla Graylog stack with a vanilla Kolide setup and a vanilla Wazuh and Moloch. These are all configured to OUR specifications and with OUR data, our queries and our pipelines and our OSSEC rules and Sysmon configurations (the list goes on), that we've consolidated over the last several months and years of experience. It is tailored to fit our needs. And it is the culmination of so many months of hard work to get it to this point.
Granted, it takes like 30 minutes for it to finish all of that. But it's so beautiful at the end when it all turns green :)
Additionally, this does not include any of the red team activities that make all of our scenarios come to life. That is an entirely separate effort in and of itself, as is the faux enterprise environment. Both of those deserve a blog post of their own.
TANGENT: I'm all for docker. I love it. But I refuse to put anything in a Docker container that doesn't belong in it. It's very much an "if the shoe fits" situation, for me. Sometimes it makes things better and more awesome, but sometimes it adds unnecessary layers of complexity. And it needs to be done right. And I will admit, I went against my gut when we deployed the scoreboard that way. Basically, we wanted it to be empty every time we deployed it. Fresh image, and bam. preconfigured, hit go, and we're off. But. That didn't work out as intended. And I apologize (because there were a lot of facepalms at DEF CON, including mine). however, most of our issues had nothing to do with it being in docker. We're working a solution for all of that, regardless, and looking at other options. To be continued.
One of the best parts about this project? We have learned at every single event what we want to change, tweak, rip out, improve, etc. This is all infrastructure as code. see something that needs adjusting? Done. It is 100% flexible. It will never be perfect, but we are still aiming for it.
At some point in the near future, we plan on automating a lot of our Windows builds as well. One thing at a time!
If you have any questions, please reach out to us. We love doing this and we pour our hearts into it. We also love nerding out and talking about it. So hit us up on Twitter or find us at an event in the future!