
Let me first say, on behalf of the Recon team, we cannot thank the community enough for joining us last week.
It was the first time we've ever run an event like this: 100% virtual, remote, and open to anyone and everyone.
It was a huge success, and we got incredible feedback. people were friendly, engaged, and having fun until the end.
Throughout the day, we noticed a lot of you in the slack channels helping your fellow teammates, and even your opponents, when they got stuck in the game. it was pretty cool to witness bringing everyone together like that.
STATS
12 hours
660 users
216 teams
385 challengesGLOBAL participation: y'all, this is epic.
The fact that we were able to share this event internationally meant the world (hah, see what I did there) to us.
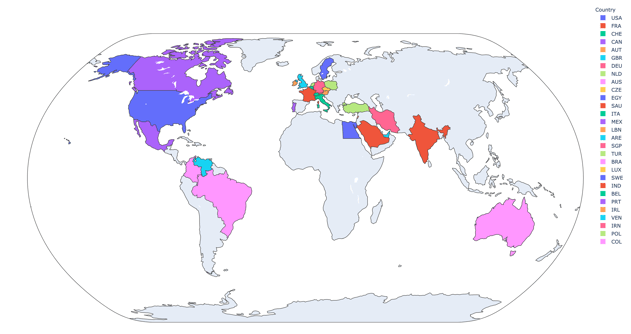
Just look at all! these! colors! 😍 Brian was able to take all of the IP data from CTFd and generate this map with MaxMind. Check out his blog post that explains all of the nerdiness that went into generating it.
{kind=link}
SCENARIOS
We ran 7 scenarios that made up the 385 challenges mentioned above.
Our team worked really hard all week to ensure that they went off without a hitch. I always say that this part deserves a blog on its own, because it absolutely does.
So much research and development goes into the scenario dev side of OpenSOC that participants never get to see (for obvious reasons).
THERE IS NEVER ENOUGH TIME.
If you are unfamiliar with how our scenarios work, check out this break down on the oldest and longest running scenario, "Urgent IT Update!!!". get all the nerdy details (read: awesome details) from Eric.
INFRASTRUCTURE
Like every event we run, we inevitably have hiccups along the way. huge live environment, lots of moving parts, hundreds of people beating it up--things happen.
BUT. It makes us unbelievably happy to be able to say that this was the smoothest event we've ever had, and the largest.
GRAYLOG
Graylog went "down" twice (down in quotes because not all nodes went down at the same time), but we now know exactly why.
And it was because of our old friend, http_thread_pool_size, that we ran into last year.
We had roughly the same player count as we did at DEF CON last year, but DEF CON was stretched across 3-4 days.
Thursday, it was 650 people hammering on our systems, all within a 12 hour window. wildly different load.
And while we had scaled all the things up with regards to CPU/memory, I naively had only quadrupled this number, instead of what I should have done, which was multiply it by 16. The first time it happened, I bumped it to 128. That held for a brief period, but it didn't take long for it to get exhausted again.
Bumped it to 256, and it was smooth sailing for the rest of the event. lesson learned. And we'll start scaling horizontally now that we have a much better baseline for that kind of load.
We could not have asked for better performance testing.
MOLOCH
This one caught us by surprise at a weird time. It was happy all day, with a couple brief periods where the viewer service caused memory consumption to get pretty high when there were so many people in there, but it corrected itself, and all was well. I had already upped resources on this system, so I was less concerned.
What I was not prepared for, was Elasticsearch being exhausted. Elasticsearch behind Moloch is a separate system, and smaller than what we have sitting behind Graylog, since Graylog gets punished a lot more during these events.
Typically, all of the scaling efforts we put towards Elasticsearch are because of so much data being ingested, not the other way around. And, as I mentioned, usually Graylog's Elasticsearch feels the brunt of this. Not Moloch's.
But, with this kind of turnout, and with so many people doing so much awesome querying, Elasticsearch was struggling to breathe, and at around 730PM EDT, it took a nosedive, and so did Moloch.
The es_rejected_execution_exception[bulk] is a bulk queue error. It occurs when the number of requests to the Elasticsearch cluster exceeds the bulk queue size (threadpool.bulk.queue_size). The bulk queue on each node can hold between 50 and 200 requests, depending on which Elasticsearch version you are using. When the queue is full, new requests are rejected.So, TL;DR, we added more juice to Elasticsearch behind Moloch. problem solved.
OSQUERY
This might have been the biggest surprise of all for me. And it was also my biggest fear going into this event.
Up until a few months ago, we relied heavily on Kolide as one of our DFIR systems in our environment(s). But, we had a lot of issues with it at DEF CON.
From DEF CON, excerpt:
a half a dozen users would query a single windows system, and the osquery agent on it would come to a halt. which meant no one could hunt on it.
we crafted a fix to clean and restart those agents on a schedule, and that worked for the duration of the event(s). this is by no means a long term fix, but it worked well enough in this case.So, to avoid this going forward, we built our own osquery frontend.
While queries to endpoints still get queued, they self-correct and we don't have to restart services, or clear out any files, or kill any processes. We simply wait for it to finish the requests in the queue and carry on.
This only became an issue when the same system was getting hammered by everyone due to everyone simultaneously working through a particular scenario.
Caveat: I've never built an application for this many people, or built any application to be used at scale. To reiterate, putting this in front of 600 people to do their worst was terrifying. I had no idea what to expect, but it held up and I was stoked.
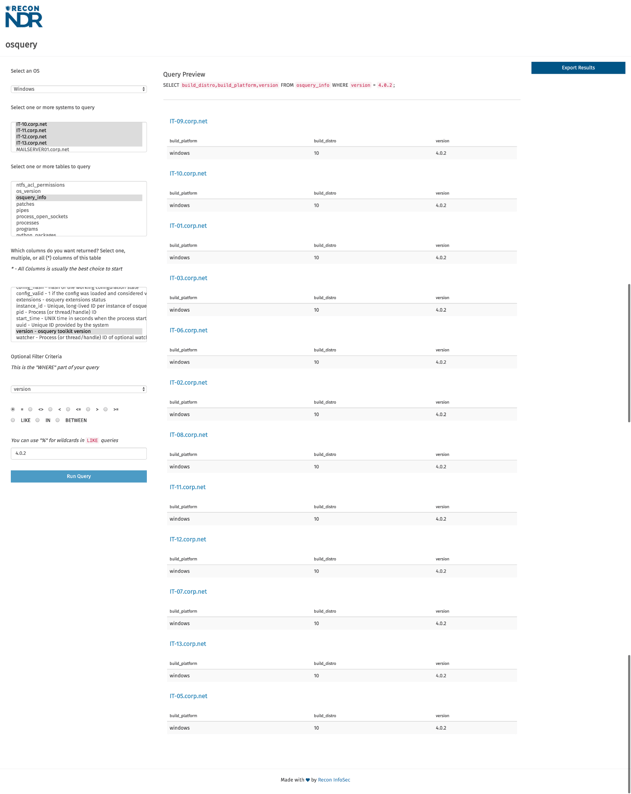
Now we just need to build in some more bumpers for folks still struggling with the query language. and osquery in general. And for the turds doing this kind of thing:
SELECT *,access,action,address,address,address,address,aliases,allow_maximum,args,arguments,atime,attributes,authentication_package,author,authority_key_id,block_size,boot_partition,broadcast,btime,build,build_distro,build_number,build_platform,ca,caption,class,class,class,class,class,cmdline,codename,collisions,command_line,command_line_template,comment,comment,common_name,computer_name,config_hash,config_valid,connection_id,connection_status,consumer,cpu_brand,cpu_logical_cores,cpu_microcode,cpu_physical_cores,cpu_subtype,cpu_subtype,cpu_type,cpu_type,crash_path,csname,ctime,current_directory,cwd,data,date,datetime,datetime,day,days,description,description,description,description,description,description,description,device,device,device_id,device_id,device_name,dhcp_enabled,dhcp_lease_expires,dhcp_lease_obtained,dhcp_server,directory,directory,directory,directory,disk_bytes_read,disk_bytes_written,display_name,dns_domain,dns_domain_name,dns_domain_suffix_search_order,dns_host_name,dns_server_search_order,driver_key,egid,enabled,enabled,euid,exception_address,exception_code,exception_message,executable,executable_path,extensions,family,family,fd,fd,file_id,file_system,filename,filter,fix_comments,flags,flags,free_space,friendly_name,friendly_name,gid,gid,gid,gid,gid,gid_signed,gid_signed,group_sid,groupname,hard_links,hardware_model,hardware_serial,hardware_vendor,hardware_version,hidden,home_directory,home_directory_drive,host,hostname,hostnames,hotfix_id,hour,hours,ibytes,identifying_number,idrops,ierrors,image,inf,inherited_from,inode,install_date,install_date,install_date,install_location,install_source,install_time,installed_by,installed_on,instance_id,instances,interface,interface,interface,ipackets,is_elevated_token,iso_8601,issuer,issuer_name,key,key_algorithm,key_strength,key_usage,language,last_change,last_run_code,last_run_message,last_run_time,license,link_speed,local_address,local_hostname,local_port,local_time,local_timezone,logon_domain,logon_id,logon_script,logon_server,logon_sid,logon_time,logon_type,mac,mac,machine_name,major,major_version,manufacturer,manufacturer,mask,max_instances,maximum_allowed,md5,metric,minor,minor_version,minutes,minutes,mode,module,module_path,month,mtime,mtime,mtu,name,name,name,name,name,name,name,name,name,name,name,name,name,name,name,net_namespace,net_namespace,next_run_time,nice,not_valid_after,not_valid_before,obytes,odrops,oerrors,on_disk,opackets,original_program_name,parent,patch,path,path,path,path,path,path,path,path,path,path,path,path,path,path,path,path,path,path,pci_slot,permanent,pgroup,physical_adapter,physical_memory,pid,pid,pid,pid,pid,pid,pid,pid,platform,platform_like,point_to_point,port,port,principal,process_uptime,profile_path,protocol,protocol,protocol,provider,publisher,query,query_language,registers,relative_path,relative_path,relative_path,relative_path,remote_address,remote_port,resident_size,result,root,script_file_name,script_text,scripting_engine,sdb_id,seconds,seconds,self_signed,serial,serial_number,service,service,service_exit_code,service_key,service_type,session_id,sgid,sha1,sha1,sha256,shell,signed,signing_algorithm,size,size,socket,socket,source,source,speed,ssdeep,stack_trace,start_time,start_time,start_type,state,state,state,status,status,status,subject,subject_key_id,subject_name,suid,summary,symlink,system_time,threads,tid,time,timestamp,timezone,total_seconds,total_size,tty,type,type,type,type,type,type,type,type,type,type,type,type,uid,uid,uid,uid,uid_signed,uninstall_string,unix_time,upid,upn,uppid,user,user,user_account,user_time,username,username,username,uuid,uuid,uuid,version,version,version,version,version,version,version,volume_serial,watcher,weekday,win32_exit_code,wired_size,year FROM appcompat_shims,arp_cache,authenticode,autoexec,certificates,drivers,etc_hosts,etc_services,file,groups,hash,interface_addresses,interface_details,kernel_info,listening_ports,logged_in_users,logical_drives,logon_sessions,ntfs_acl_permissions,os_version,osquery_info,patches,pipes,process_open_sockets,processes,programs,python_packages,registry,scheduled_tasks,services,shared_resources,startup_items,system_info,time,uptime,user_groups,users,windows_crashes,wmi_cli_event_consumers,wmi_event_filters,wmi_filter_consumer_binding,wmi_script_event_consumers WHERE cmdline LIKE '%dll%';Some people just want to watch the world burn.
CTFD/SCOREBOARD
We have had so many scoreboard woes over the years. Platforms that scaled, but basic features were broken, or imports/exports were unreliable. Platforms that had all the things, but didn't scale.
We decided we wanted no more of that.
We finally caved and got a subscription with CTFd to host our scoreboards going forward. Their team has been super responsive anytime we've had an issue, and last Thursday went ALL DAY without a single "THE SCOREBOARD IS DOWN!!!"
It was beautiful. So, thank you, CTFd team. Nailed it.
THANK YOU, AGAIN
We hope you all had as much fun as we did (hopefully more). We love running OpenSOC--it is really a labor of love for this team. And it truly takes the entire team, especially for an event this large.
We thrive on giving back to a community that has provided us with so much of what we use and rely on.
We hope to see you guys at OpenSOC in the blue team village at DEF CON (if there is a DEF CON this year), or at Black Hat (if there is a Black Hat this year), or both! :)